This page discusses why Musa is allophonic rather than phonemic. We'll start with a brief exposition of the problem, using examples from English.
Lexical Phonology
To speak and understand a language means to be able to convert from meaning to sound and vice versa. The diagram below shows four levels in this conversion, including the ones we consider to be part of phonology. To the left of the morpheme is the lexeme, the root. To the right of the phone is articulation and acoustics.
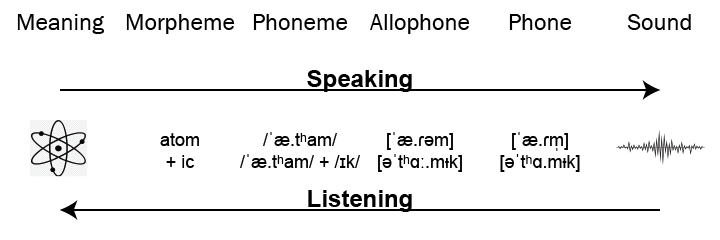
The idea of this diagram is that, as words move from left to right, they transform, becoming closer to sound and further from meaning. The diagram portrays the voyage of two English words, atom and atomic.
You probably learned the word atom in Chemistry class at the same time that you were introduced to the concept it names. Perhaps you were also told that the word means indivisible or uncut, derived from ἄ-τομος in Ancient Greek. And you probably learned the adjective form atomic at the same time, which just adds the common adjectival ending -ic to the noun. Atom and -ic are morphemes; the word atomic is lexicon.
Your Chemistry teacher probably pronounced the word atom as if it were spelled using English spelling conventions: the a as in pat and the o as in pot, even though that's not how it was pronounced in Ancient Greek, nor even how it's pronounced now in most other languages, where the a would be pronounced as in father and the o as in most. But it's normal that the word was "anglicized" as it came into English, and that's what's shown as the phonemic level.
Once past the phonemic level we're in phonology, where various processes transform the words. One of these processes is called vowel reduction, whereby the unstressed vowels in a word become weaker, both saving effort and helping to indicate which syllable is stressed. In both the noun atom and the adjective atomic, the stress falls on the penultimate syllable. In the noun atom, it's the first syllable that's stressed and so the second is reduced: the o becomes a schwa. But in the adjective atomic, it's the second syllable that's stressed and so the first and last are reduced: the a becomes a schwa, and the i becomes near-mid central ᵻ.
Another phonologic process replaces the plosive t of atom with a tap. This process also affects a d in the same position: intervocalically before an unstressed vowel. So Adam is pronounced the same as atom. Because of this process, word pairs like metal and medal sound alike. This transformation doesn't occur in atomic because the t comes before a stressed vowel. But another process operates in that context: when an unvoiced plosive (p t ch k) starts an initial or stressed syllable, it's aspirated - the t becomes tʰ.
Well, that last isn't quite accurate. In English, as in some other Germanic languages, the phonemic opposition is between fortis and lenis, not unvoiced and voiced. The fortis plosives are normally aspirated, and the lenis ones partially voiced. But this basic contrast is muddied by fairly complex changes. For example, fortis stops often lose the aspiration midword, whlie lenis stops are fully voiced between voiced segments. There are quite a few different cases.
The result of these phonologic processes is that the noun atom and the adjective atomic now share only one sound: the m. We call this the allophonic level: we write the allophones in Musa. And this is the level of lexicon, because all these transformations take place within a word, regardless of the other words around it. It's at this level that Musa spells words.
But words don't occur in a vacuum - they occur in an utterance, and that affects how they're pronounced. The diagram above shows a couple more changes that might occur when speaking quickly: the word atom might end in a syllabic nasal, and the o of atomic might not be held as long as normal. But we don't show these in the Musa spelling. We also don't spell the full detail of the pronunciation at the phonetic level, such as whether the t is dental, denti-alveolar, alveolar, apical or laminal. We only show the level of lexical phonology.
Orthographic Depth
But this seems like a lot of trouble! Why don't we just skip it, and communicate meaning directly? Well, that sounds great ... but we just can't seem to do it. Until a few thousand years ago, the best we could do was convert meaning to sound, transmit and receive sound, and then reconvert the sound back to meaning.
But then we invented writing, which enables us to communicate across time - from the past into the future - and/or across space, between two people who are physically distant. It also lets us multiply our listeners far beyond the range of our voices, especially once we learned how to reproduce the written media via printing. Writing is the most important invention humanity has ever come up with!
The first writing was at the level all the way to the left, at meaning: Sumerians drew (using a stylus in clay) a stylized head of a cow ∀ and then some tally marks ||| to show how many cows were involved. This logographic approach is totally independent of language, and sure enough the modern logogram 日 means "sun" or "day" in every language that writes this way, even though it's pronounced rì in Chinese, jaht in Cantonese, nhật in Vietnamese, il in Korean, nichi or jitsu in Sino-Japanese, and hi or ka in native Japanese.
But it turns out not to be possible to describe everything using only images, so all the logographic systems - Sumerian cuneiform, Egyptian hieroglyphics, Chinese characters, Mayan writing - ended up as a mix of meaning and sound. For example, the Chinese character 問 is a combination of the symbol for a mouth 口 and the symbol for a gate 門. This last is pronounced mén, but its meaning isn't important here - it's being used for its sound value. 口 is pronounced kǒu, but we don't care - it's being used here for its meaning: something to do with speech. Thus 問 represents a word that sounds like mén, but has something to do with speech - it means ask, which is pronounced wèn.
Some people say that Chinese writing needs to indicate meaning because Chinese has so few possible syllables (only about 1300, a sixth of English) that it has many homophones, which would be confused if Chinese writing only represented sound. But of course Chinese people manage to understand each other when speaking, which is only sound. Korean used to be written with Chinese characters (hanja), but they invented an alphabet 500 years ago and now write only sounds, with great success.
In about 1850BC, Canaanite miners working on an Egyptian project to mine turquoise in the Sinai saw how the Egyptians communicated using symbols, but they couldn't read them (or understand the Coptic language). Nonetheless, they began using simplified versions of those symbols for their sound values, thus inventing the first alphabet. From Proto-Sinaitic derive all the alphabets of the world. They wrote only consonants, since the vowels can be inferred in Semitic languages, but the Greeks added vowels and Musa adds prosody: stress, register, tone and intonation. The first alphabets enabled people to record spoken language without representing meanings, and subsequent developments have made it possible to do that with more and more fidelity.
So do alphabets represent only sound? No - English spelling also reflects meaning, morphemes, etymology, historical pronunciations, other dialects, and pretension. English has homographs like read (present) and read (past), homophones like read (past) and red (color), and near-homonyms like address (noun and verb) that differ only in stress. It has sets of words like tough though thought through that are hard to explain. And yet spoken English is not hard to understand. It's probably easier to understand spoken English, which carries no information about meaning, than written English, which does!
English has one of the worst writing systems of the world, along with Japanese and French. At the other end of the spectrum are languages like Finnish or Serbo-Croatian (in two alphabets!), with very good writing systems. The trick is shallow orthography: words are pronounced as they are written, and written as they're pronounced. Musa and other phonetic alphabets are trying to capture the sounds of the spoken language, secure in the knowledge that listeners understand that.
Allophones versus Phonemes
We all agree that shallow orthographies are better. But what does this all have to do with the question of whether to represent sound at the phonemic level or the allophonic level? Aren't phonemes sounds? Well, no - phonemes are a level or two removed from sounds. Here are some examples, taking advantage of the digression we made above into fortis and lenis plosives in English.
The two English phonemes, lenis /d/ and fortis /tʰ/ are manifested as at least four different allophones: devoiced [d̥] and aspirated [tʰ] at the beginning of most syllables, unvoiced [t] and voiced [d] intervocalically, unvoiced [t] after [s], and devoiced [d̥] and held [t̚] at the ends of most syllables. Many dialects add a flap [ɾ] intervocalically after a stressed syllable before an unstressed syllable, or a glottal stop [ʔ] in several positions. If each allophone corresponded to only one phoneme, then differentiating all that would be over-representation. But that's not the case: several of these allophones can represent either lenis or fortis phonemes. The result is under-representation at the phonemic level.
When an English speaker hears [ˈæ.ɾəm], he doesn't know whether the phonemic form is /ˈæ.tʰəm/ <atom> or /ˈæ.dəm/ <Adam>. In German, [ʁaːt] could be Rat or Rad, and so on in many other languages. In cases like these, you can't progress from allophone to phoneme without relying on the meaning.
But when it comes to reading, isn't that a Good Thing? Aren't we happy to give the reader an extra clue to the meaning in the form of different spellings? No, that just makes the orthography deeper, more obscure. And in fact, if you learned the words before you learned to read and write, as is often the case in our native languages, then you may not associate the spelling with the meaning. That's why we often make spelling errors in very common words, like there their they're or your you're.
Of course, we recognize familiar words no matter how they're spelled. But deep orthography isn't better with rare words. Consider the examples of caret carat karat carrot, which are all pronounced alike. With morphemic spelling, we can say they're homophones, and the writer who wants to use one of them has to know which one and how it's spelled. That's what we do now. Or we can say, with phonetic spelling, that they're homonyms, and they're all spelled [ˈkɛɹ.ᵻt]. The latter results in far fewer spelling errors, and fewer pronunciation errors. Don't the different spellings help differentiate the meanings? Very few people can correctly assign all four meanings to the correct spellings.
Consider the following words:
| Morphemic | Lexical | Phonetic |
|---|---|---|
| leave (verb) + 3p sg pres | leaves | [liːvz] |
| leaf (noun) + plural | leaves | [liːvz] |
| leaf (verb) + 3p sg pres | leafs | [liːfs] |
Here, a deep orthography would spell the plural of leaf as leafs (just as we now spell the plural of roof as roofs). If we did that, it would become a homograph of leafs, as in "He leafs through the book". I hope none of you favor that approach, even though the spelling leafs would give readers an extra clue to the meaning.
Some people think of writing as moving to the right in the diagram above, and so they think that allophonic orthography is more work: there are more allophones than phonemes, so you have to specify more to write allophones. But that isn't true! If you want to write about the size of a diamond, it's YOU the writer who has to remember whether it's carat, caret, or karat. Think about it: ALL spelling mistakes are made by the writer, not the reader. And in fact if you wrote that your ring was made of 24 carrot gold, the reader might not even notice. If he did, he might chuckle at your lack of education, but he'd understand what you meant. If the orthography was allophonic, you'd just write kérit without having to think about it. Phonemic orthography is harder, not easier than allophonic orthography.
Meanwhile, phonemic orthography seems very odd to the reader. Look at the two most popular romanizations of Japanese, for example. With a few footnotes, Japanese syllables consist of one of a dozen or so consonants plus one of five vowels - they form a very regular grid called the gojūon. But numerous such mora feature pronunciation changes: ti si zi are pronounced chi shi ji, and so on. The most popular romanization, Hepburn, spells out those changes, while the official government romanization, Kunrei, doesn't. In Hepburn, the name of the famous mountain is Fuji; in Kunrei, it's Huzi. As a reader, which do you find more important: that the spelling match the sound, or that it tell you the abstract phoneme that the sound derives from?
It would be easy to present more examples, for instance from Korean, where assimilation of internal consonants makes morphemic and phonetic forms quite different - think of English cupboard or boatswain. But they're not needed - my point has been made: we don't want meaning in our spelling, at all. We want the spelling to represent sound, and nothing else. Spoken language is a way to represent meaning with sound, and we should take advantage of it wholeheartedly by writing sound. After all, we already know that people can convert sound to meaning without writing!
Orthography for Foreigners
Musa's allophonic spelling has some other advantages. It's much easier for people to learn a foreign language - one they learn after they can already read and write in their native language(s) - when the spelling is as phonetic as we can make it. These people don't know the phonology, not even unconsciously like natives. They don't know that aspirated t loses its aspiration after s or at the end of syllables. They may not even know that it's normally aspirated! But when, in Musa, we write it as aspirated, they can read it without having to learn any phonology or rules.
This is almost as true of words in our native language that we encounter first in their written form, like hegemony or segue. Yes, we could pause in our reading to look them up in a dictionary with pronunciation, but we often don't, and so we don't know how to pronounce them. That's especially the case with loanwords from other languages which we import without changing the spelling, like paella or karaoke, and which sometimes have sounds that we don't have in English.
Foreign names are another big beneficiary of Musa's allophonic spelling, since we don't usually respell them. If you can't pronounce the guttural r of [paʁi:], at least you can say [paɹi:] instead, but still spell it correctly. And cases like [wuʨ] turn out not to be too hard to pronounce in English, although you'd never figure that out from the Polish spelling Łódź. With phonemic spelling, how would we spell sounds that aren't English phonemes?
One of the great advantages of Musa is that it's a universal alphabet: not only can every language be written with the same letters, but they represent the same sounds. If we want our alphabet to serve other languages - and we do! - then we have to write our own language so that speakers of other languages can read it. That's not possible with phonemic orthography, since every language has its own phonology.
But what about psychological reality of the phoneme, the idea that people intuitively recognize phonemes but only with difficulty distinguish allophones. I'm skeptical of both halves of that assertion.
In Old English, unvoiced and voiced fricatives were the same phonemes, with allophones /v ð z/ intervocalically and /f θ s/ otherwise. But after the Norman conquest, they all became independent phonemes. And there are many other examples from many languages of phonemes merging and splitting. Do people suddenly realize one day that f and v sound different?
Another line of evidence comes from dialectal differences. For example, in some English dialects, north and forth don't rhyme; in others, they do. Likewise for Mary marry merry and many other examples. In fact, the whole idea of lexical sets is an alternative to phonemic analysis.
Another line of evidence comes from writing systems, which often diverge radically from phonemic analysis. If phonemes are so evident, where are they in our alphabets? Syllables seem much more evident.
To some degree, it's trivially true that the closer a level is to meaning, the more psychological reality it has, since it is meaning that is the origin and destination of the whole two-way process. And writers will always favor under-representation out of laziness. Think of the little bird Woodstock in the Peanuts cartoons: his script is very simple to write, but very hard to read.

But readers will always prefer over-representation, and these days, written text is often read more than it is written, and it's usually written on a keyboard, sometimes even with a spell-checker. A well-designed shallow orthography makes it easier to avoid under-representation.
Spaniards often confuse the letters b and v, since they are the same phoneme in Spanish: Valencia starts with a V pronounced like b, and Córdoba features an intervocalic b pronounced like v, and Spaniards supposedly can't hear the difference. But they very rarely confuse the letters c and qu, even though they also represent the same phoneme /k/ - they never write ceso for cheese or quasa for house - because they learn spelling rules: /k/ is written c before a o u and qu before i e. If Spanish had a spelling rule that said "write b at the beginning of a word or after a nasal, and v otherwise", there would probably be very little confusion, and the graphemes would match the phones. And Spaniards would all say that they can hear the difference easily!
We teach phonemes to our children when we teach them to read and write. That's why the Chinese never developed an alphabet until Bopomofo in 1928, and even that doesn't recognize the unity of initial vs. final consonants or onglides vs. offglides. It seems that Chinese don't recognize them as the same phonemes, and yet we claim that initial, medial and final /w/ are all the same phoneme. Meanwhile, the Chinese series of palatals written j q x in pinyin is in complementary distribution with the similar-sounding zh ch sh series, and yet everybody insists that they aren't the same phonemes.
If you're interested in thinking more about the theoretical underpinning of phonemes, here's a page in which I talk more about it:
But for those of us not interested in debates about what is or isn't a phoneme, let's just write allophones. Phonemes are not the underlying reality behind phones, as some theoreticians claim. Instead, they are intermediate forms in various models trying to explain the surface phonetics. Maybe it would be clearer if we called them "phonettes" or "phonelings": they're collections of phonetic features that may someday become a sound when they grow up. The only underlying reality is the final phonetic form, and that's what we write.
| © 2002-2025 The Musa Academy | musa@musa.bet | 05apr25 |