When we use Musa to write a language, we call it Allophonic transcription: we write the allophones of the language. But phoneticians and others need a more detailed notation, which we call Orthophonic transcription. For example, they might want to describe a particular utterance, or the pronunciation of a particular person, or a particular dialect. Here's an illustration of the difference:
| Roman | Musa | ||
|---|---|---|---|
| Orthography | tryout | | Allophonic |
| IPA | [ ˈṯʃʰɹ̱̊äɪ̯ˌä̟ʊ̯̆t̚ ] | | Orthophonic |
The Orthophonic Musa is much cleaner and easier to read than the IPA. It contains in eight Musa letters and one accent the same information as eight IPA symbols plus thirteen diacritics. The only differences between the two Musa versions are the vowel digraph, the explicit pre-fortis clipping, and the specific allophone of the rhotic approximant – the voiceless postalveolar. Normally, when we write English, we use the rhotic semivowel to show that several pronunciations are acceptable. But when we're talking about a specific utterance, we specify it.
Professionals can also use orthophonic transcription to describe disordered speech, the result of a physical problem like a cleft palate or throat surgery, or a neurological problem. And we also use orthophonic transcription for unusual voicing, like percussive consonants or hollow voice. Orthophonic transcription also gives us the tools to describe a vowel very precisely. Musa orthophonic transcription thus plays the roles of many IPA diacritics, of the Extensions of the IPA, and of the VoQS Voice Quality Symbols. Perhaps Musa can't write everything they can, but we can get close.
On this page, we'll describe how to use it.
Levels of Transcription
Just a word about terminology. The phrase The Musa Alphabet refers to the entire script, in all its variants. When we say that English, French, Chinese, or another language is written in Musa or in the Musa Alphabet, we mean normal writing: practical allophonic orthography, the equivalent of the IPA's broad phonetic transcription.
When we refer to Musa as a Universal Phonetic Alphabet, we mean an allophonic transcription targeted for use by the public, both natives who speak the language and foreigners who don't. Usually, normal Musa orthography is sufficient, but UPA can be narrower and less standard. For example, most Americans pronounce the name New Orleans as [ˈnuw ɔɹlˈijnz], but the locals pronounce it [nuw ˈɔɹlᵻnz].
Finally, the phrase Musa Phonetic Alphabet refers to orthophonic transcription, as used by linguists and described on this page, the equivalent of the IPA's narrow phonetic transcription.
Vowel Digraphs
The IPA has 28 vowel letters, while Musa has only 20. What's missing?
Well, the IPA's central vowels. The Musa vowel triangle is based on the acoustics of vowels, not their articulation. Acoustically, front rounded vowels are more central than front unrounded vowels, and back spread vowels are more central than back rounded vowels, and between them there's no room for central vowels. Here are IPA and Musa vowel charts based on acoustics:

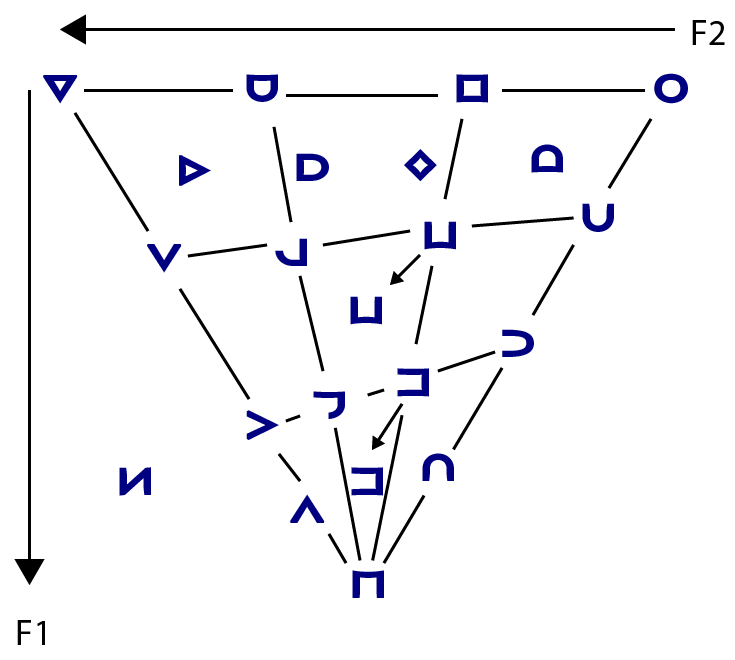
The IPA vowel chart at left omits nine central IPA vowel symbols ʏ ᵻ ɨ ʉ ɘ ɵ ɜ ɞ ɶ. The Musa chart at right restores the first two - ʏ ᵻ - but merges ɑ ɒ and merges ə ɐ into ɤ ʌ.
Don't we need those missing vowel letters? Why would the IPA have them if we don't need them? Well, most of the reason is historic: the IPA based its vowels on an articulatory model that nowadays seems obsolete. But phoneticians still use those symbols. For example, the ɵ symbol spells the French e caduc … or is it more an ə, an œ, or an ø? All have their champions, because the actual range of sounds encompasses all of those symbols. They're too specific for use with a real language.
But phoneticians need to be able to specify vowel sounds more precisely, to characterize an allophone, an accent, or a single utterance. In such cases, Musa uses a notation called Vowel Digraphs: we write vowel sounds with a sequence of two Musa vowel letters. In normal Musa text, vowels are never adjacent, so there's no ambiguity.
The idea is very simple: the first of the two vowels is the closest Musa vowel letter to the intended sound, the one that would be used in an orthography, and the second vowel shows the direction of the refinement. To reuse the example of the French e caduc, we'd write it as : is how it's written in French, and shows that it's slightly rounded and slightly fronted.
The following chart shows the Musa vowel digraph equivalents of all the missing IPA vowel symbols:
| ɨ | ʉ | ɘ | ɵ | ɜ | ɞ | ɶ | ɒ | ə | ɐ |
|---|---|---|---|---|---|---|---|---|---|
| | | | | | | | | | |
This vowel digraph notation also replaces the IPA vowel diacritics for raising o̝, lowering e̞, fronting o̟, backing e̠, centralizing ö, and mid-centralizing e̽. Here are the modified vowels from the Wikipedia page on vowels:
| e̞ | ø̞ | ɤ̞ | o̞ | ä |
|---|---|---|---|---|
| | | | | |
Your use of this notation shouldn't be limited to these examples. The vowel pairs can be horizontal, vertical, or diagonal, and can mix spread and round vowels - generally, a different rounding is indicated by the second vowel. If the second vowel is a little further than adjacent, it generally indicates a narrow diphthong. Vowel digraphs are a very powerful method of indicating a precise combination of formants and rounding.
Orthophonic Affixes
Musa offers three sets of affixes for unusual consonants. We call them orthophonic affixes. The first adds unusual positions.
Orthophonic Positions
Normal Musa consonants offer 16 positions of articulation. We say "positions of articulation" instead of the more common "places of articulation" because we include not just the active and passive articulators but also some other relevant factors. For example, we distinguish between sibilant and non-sibilant sounds in both coronal and retroflex positions, even though they use the same place of articulation. In fact, the palato-alveolar (postalveolar) sounds are mostly distinguished by the shape of the tongue, not its position. We also distinguish laterals from other coronals as if they were a different position, and we consider labio-velar sounds to be a "position", one that happens to involve two articulations. Finally, we consider glottal sounds to be a "position", although in fact they have no position: a better name might be "glottal-only".
Musa orthophonic notation offers another 18 positions of articulation as suffixes, all with a Wa top. To use them, write the Musa letter with the correct manner of articulation as a top, with a Yu bottom. Then write the orthophonic position suffix, with Wa as top and one of the following as bottom. That digraph spells the sound with the manner of the top of the first letter, and the orthophonic position of the bottom of the second letter.
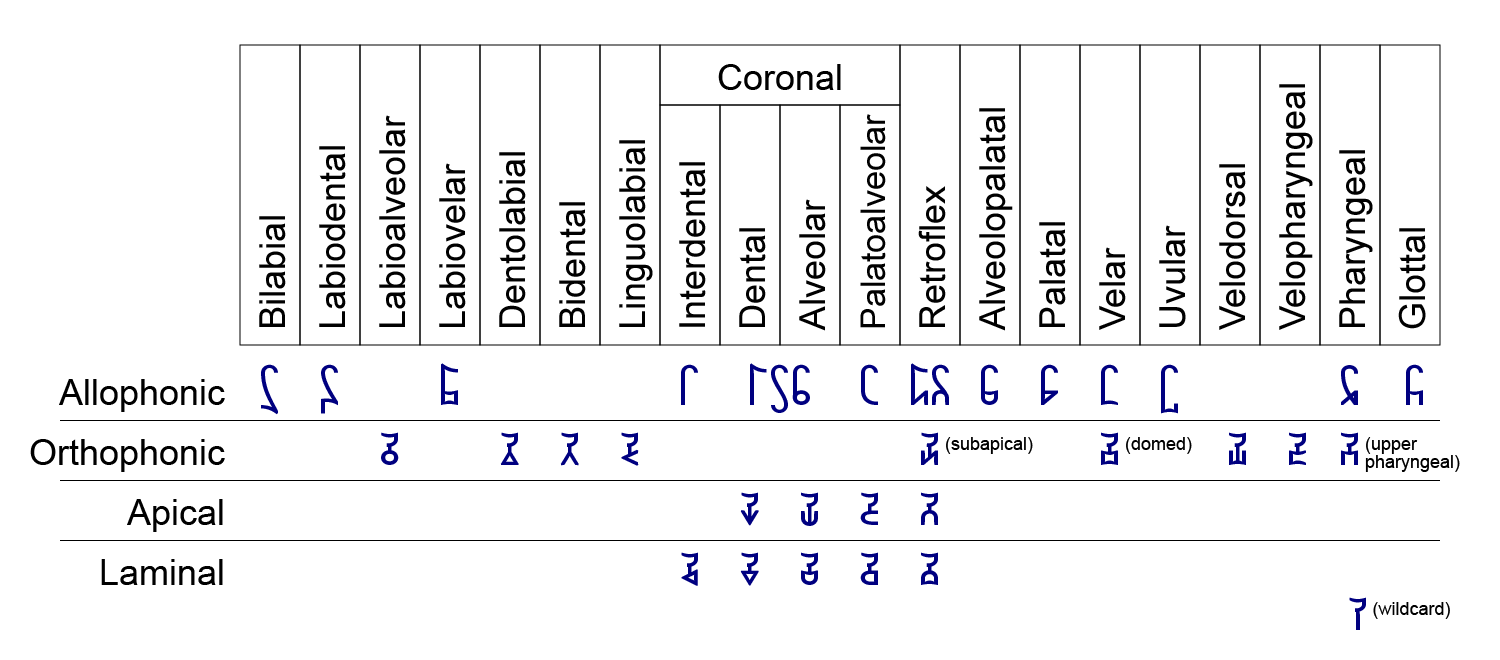
As you can see, this notation allows you to distinguish between apical and laminal articulations of coronal sounds. For example, the s and ts sounds of Basque are apical alveolar, while the contrasting z and tz sounds are laminal alveolar. There are also postalveolar x and tx, which we write using allophonic letters. Here's how we'd write them:

Many languages have laminal alveolars , often spelled s and ts, but when writing Basque, we write even those sounds with orthophonic letters. That's because the normal coronal letters stand for a broader range than the Basque sounds. We also use orthophonic letters for retroflex sounds when a language uses two of them.
The other orthophonic positions are all unusual: labioalveolar, linguolabial, dentolabial, bidental, interdental, velodorsal, velopharyngeal, and upper pharyngeal. American th, both voiced and unvoiced, is often interdental, but we write it with allophonic letters as a non-sibilant fricative, to subsume the British dental articulation. There's also an orthophonic suffix for a domed, bunched, or molar tongue shape, as in one common realization of American r. Finally, there's a "wildcard" suffix for a position that isn't among these.
In addition to the positions shown above, we offer two flexible letters that show relative position of articulation, either advanced or retracted. The bottoms are the Musa digits for +1 and -1, both upside down. They duplicate the function of the allophonic advanced and retracted suffixes - you'll see why, below.
| Advanced | |
| Retracted | |
Unlike all the suffixes above, these are preceded by a normal Musa letter, which may or may not have a Yu bottom. For example, we could use these suffixes to describe how the k sounds in keep and coop are advanced and retracted relative to the neutral k in cup:
| | | |
| keep | cup | coop |
Orthophonic Manners
Musa orthophonic notation also offers unusual manners of articulation, also using the Wa shape. But in this case, the Wa is used as a bottom, and the letters are prefixes, not suffixes. The top of the prefix shows the manner, while the position of articulation is the bottom of the following letter, whose top is always Yu. Note that the tops are all closed shapes, to show that the effect is only applied to the following sound.

For example, here are three bilabial letters from the Extensions to the IPA:
| nasal fricative | denasal | percussive |
|---|---|---|
| | | |
| m͋ | m͊ | ʬ |
When both the position and the manner are orthophonic, we use two orthophonic letters. The first is the orthophonic manner prefix, with an upside-down Wa bottom, and the second is the orthophonic position suffix, with a right-side-up Wa top.
| |
| ʭ |
|---|
Orthophonic Airstreams
Musa has notation for unusual (alaryngeal) airstreams: ways to make air come out of your mouth without using your larynx. This notation uses prefixes like orthophonic manners, but the tops are all open shapes, to show that the effect is applied to all the following sounds until the laryngeal airstream prefix replaces it, setting the airstream back to normal. That's because people rarely change airstreams: if you speak with a tracheo-esophageal prosthesis or an electrolarynx, you're not going to change mid-sentence! Unlike the manner prefixes, the airstream prefixes are written with a space after them.

Orthophonic Phonation
Finally, Musa has notation for unusual phonation. The Musa allophonic letters mostly rely on the simplest phonation mechanisms, of which there are three: unconstrained breath, in which air simply flows out of the larynx with frictional turbulence to power voiceless sounds; modal voice, in which the vocal cords are vibrating at their modal (optimal) frequency; and a completely closed glottis, as in a glottal stop and some held (unreleased) stops.
In this simplest model of voicing, airflow is either off or on, and if it's on, voice is either off or on - the rest is timing and the action of other articulators downstream. Musa uses voiced and implosive letters to spell sounds for which voice is on, and voiceless, aspirated, held, and ejective letters to spell sounds for which voice is off.
Musa also offers allophonic letters for breathy voiced stops (usually just called "breathy" stops), since they occur in most of the Indo-Aryan languages. When the same voice is applied to sonorants, we call it murmur. But breathy voice can also be a phonation, in which it applies to all voiced sounds over a longer utterance. In breathy voice, the vocal cords are held more loosely than in modal voice, and vibration only occurs along part of their length. When we say that a segment of speech is "breathy", we mean that the voiced sounds are pronounced with breathy voice, while the voiceless sounds use normal breath.
The opposite of breathy is creaky, a phonation in which the vocal cords are held more tightly than in modal voice. This is the phonation responsible for the "vocal fry" of country singers and Valley girls, but some languages use it in normal speech. When we say that a segment of speech is "creaky", we mean that the voiced sounds are pronounced with creaky voice, while the voiceless sounds use normal breath. Sounds can't be both breathy and creaky at the same time.
Some languages use breathy and creaky voice, but only lightly, partially. For those languages, we offer affixes for slack (slightly breathy) and stiff (slightly creaky) voice.
You can also stretch the glottis itself, which raises the pitch of the sound passing through it. We call the resulting effect falsetto.
Above the glottis is a tube called the epilarynx. When you squeeze it as you speak, you add more turbulence and make the sound louder: we call that whisper. While you whisper, any voiced sounds you make are said to be spoken with whispery voice.
Inside the epilarynx, above the vocal folds, are another set of folds called the ventricular folds. They can vibrate alongside the vocal cords; this is called ventricular voice.
At the top of the epilarynx are a third set of flaps - the aryepiglottic folds - that can be controlled independently of the glottis and epilarynx. When these folds are tightened, the result is harsh voice. When you're speaking in a low pitch, the aryepiglottic folds can even be made to vibrate (to "trill"), and thus to produce sound. That's how we growl.
When you stretch your glottis out with falsetto but also squeeze the epilarynx with whisper or harsh voice, you can create enough tension so that the glottis is pulled closed, as with a glottal stop, but high pitch sounds can force their way through. That's called pressed or tight voice.
The entire larynx itself can be raised, a gesture often accompanied by retraction of the tongue, to shrink the volume of the pharynx (the area between larynx and tongue). When you speak with a raised larynx, it's called by the very unimaginative name of raised-larynx voice when the sound is high-pitched. When the sound is low-pitched, it's called pharyngealized voice.
The opposite is unsurprisingly called lowered-larynx voice: the pharynx is enlarged. When the sound is high-pitched, it's called hollow voice or faucalized voice.
Many of these phonations can be combined, in the sense of independently controlled. That doesn't mean that they're independent - quite the opposite! They usually affect each other quite a bit, with the result that it's not easy to identify which aspects of the sound result from which active laryngeal articulations and which concomitant effects.
There are a few other voices that are easier to understand. One is simply silence: you move your mouth as if you were speaking, but with no air coming out, there's no sound! We also have symbols for strong and weak voice, just talking about the force of the airstream.
This brief survey of a very complicated topic suffices for the purpose of introducing Musa's orthophonic affixes for phonation, but if you have questions, it's not me you should ask! Instead, I recommend the definitive treatise on this topic, the 2019 book Voice Quality: the Laryngeal Articulator Model, by Esling, Moisik, Benner, and Crevier-Buchman, and it's their terminology from the LAM that I am using here. Some of the terms above are used with different meanings in other sources, for example in the VoQS.
Musa offers orthophonic affixes for all the phonations described above. One big difference between orthophonic phonation and the orthophonic articulations you met above is that phonation often applies to a longer piece of speech than one single sound. However, unlike the airstreams, it can change in mid-sentence. If you want to write a breathy stop or a creaky vowel, you can do that with allophonic letters, but if you want to show that an entire word, phrase, or sentence was pronounced in a whisper, or a falsetto, you need to use a pair of orthophonic phonation affixes: the first to signal the start of the phonation, and the second to signal its end. The first is a prefix with a Ma top, and the last is a suffix with a Ma bottom. For example, here's a short sentence in the Roman alphabet with Musa orthophonic phonation letters, in which the name "Parramatta" was whispered:
| The secret code is Parramatta . |
|---|
By convention, there are spaces next to the phonation affixes. And if the closing suffix appears without a preceding opening prefix, it means that the phonation applies only to the previous segment: if you want to write that only the last consonant is creaky, follow it with a (with no space).
Here are the phonation affixes, one opening prefix and one closing suffix in each pair:

The affix for Modal voice isn't really needed, since we assume that when an unusual phonation ends, what follows is in normal voice. But it's a convenient way to end a long sequence of prefixes, since these symbols are often combined. For example, to write a phrase in harsh whispery creaky falsetto, which VoQS would write as F̰̣!, Musa would write (in any order) as a prefix, but then you could end it with a simple .
Here are the phonations from the 2016 VOQS chart, with the Musa opening prefixes superimposed:
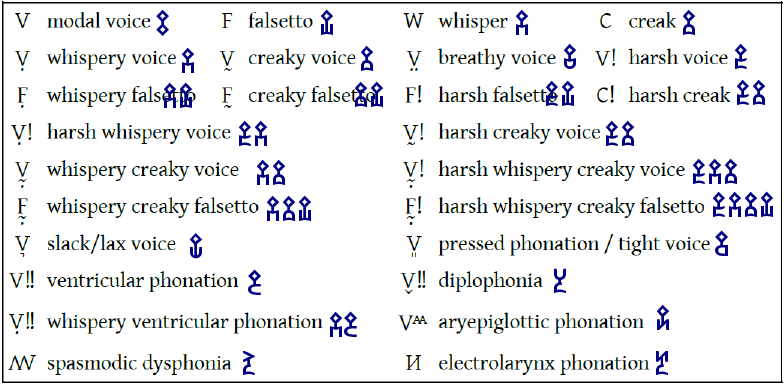
These affixes can even be combined with themselves. In VoQS, the symbols may be modified with a digit to convey relative degree of the quality, e.g. 3V! spells very harsh voice. In Musa, we just repeat the symbol: very harsh voice would be . To then reduce the degree to 2V!, you only need to write and continue.
For example, here’s the illustrative line at the bottom of the VOQS chart:
On the last line of the chart above, there are two pairs of "wildcard" affixes: one for more airflow and less voice, the other for more voice and less airflow. They're used for odd phonations that aren't on this chart.
Finally, there's a pair used to indicate secondary articulations, using suffixes after the opening prefix(es). If it's velarized nasalized whispery creaky voice (the example from Wikipedia: Ṿ̰̃ˠ), you can just write . But if it's something obscure, like "left-offset jaw" or "palato-alveolarized", just write left or pal-al - don't make your poor readers consult a chart of tiny diacritics.
Partial Phonation
The Extensions to the IPA for Disordered Speech (extIPA) uses very small parentheses around subscripts or superscripts to represent various odd timings of phonetic features. For example, partial central devoicing of a z would be written z̥᪽, while partial initial devoicing would be z̥᫃, and partial final devoicing would be z̥᫄. Font support is spotty, but the larger problem is that the notation is too small to be easily read.
The Musa equivalent uses trigraphs, trios of almost-repeated letters. A duo might represent a legitimate geminate, but a trio is unambiguously orthophonic. The same three phonations shown above would be spelled zsz for centrally devoiced z, szz for initially devoiced z, and zzs for finally devoiced z. The same idea can be used for other phonetic features such as aspiration, nasalization, creakiness, murmur, or lack thereof. To spell the feature without the base sound, use the orthophonic affixes you met above. For example, a pre-voiced z, extIPA ˬz, could be written .
Connected Speech
Slurred or sliding articulations are written as digraphs, e.g. for s͢θ. Stuttering is just written as repetition, e.g. for p\p\p
The extIPA uses mid-dots in parentheses to indicate pauses of various lengths; Musa uses a mid-dot as a normal word separator (in Dushan Musa Alphabet font, which we recommend for orthophonic transcription), and adds more dots to indicate longer pauses.
The extIPA uses Italian musical terms to indicate tempo: forte piano fortissimo pianissimo allegro lento etc. You can do the same in Musa using the secondary affixes, with the opening prefix followed by the tempo, or just the abbreviation .
Missing Notation
There are probably some extIPA symbols that don't yet have a Musa homologue. Most likely, the extIPA itself is missing useful notation. Either way, Musa isn't set in stone (an advantage of not being in Unicode).
Orthophonic Tones
The normal Musa tone notation enables you to indicate which tone a syllable bears, but it only indicates in general terms how it's pronounced. If you need to spell out a tone contour acoustically, we use a different system, orthophonic tones.
Orthophonic tones play the roles played by the well-known Chao tone letters. However, instead of using a pentatonic scale with five pitch levels, we use a hexatonic scale with six pitch levels (here shown with a "carrier" vowel):
-
Very high (5)
High (4)
Mid high (3)
Mid Low (2)
Low (1)
Very low (0)
The length and contour of the tone is then spelled out with these orthophonic tone accents, which are always written on their own, not above or below the vowel. The offglide or final follows them.
For example, the Chinese word 馬 or 马 mǎ is third tone, and would normally be spelled . But when describing the tone in more detail using orthophonic tones, we would write : the tone contour starts low, dips down even further, then rises up but not too far (orthophonic transcriptions are normally in Alphabet gait). To lengthen a tone, just repeat the accent.
To write creaky voice or a glottal interruption, use the long mark of the appropriate height. For example, to spell out one version of Vietnamese's ngã tone, you could write : the tone contour starts high, dips down a little, gets interrupted, and then rises all the way up.
This same approach could be extended to intonation marks, both tonics and finals. In both cases, the first mark should stay as it is in normal allophonic transcription, and then you can describe the pitch excursions in more detail using the system described here.
| < Musa as a Phonetic Alphabet | Other Phonetic Tools > |
| © 2002-2025 The Musa Academy | musa@musa.bet | 26jan25 |